
[ad_1]
Generative AI algorithms use likelihood to build visuals from sound
Previous 12 months the Internet bought its first flavor of impression-generating synthetic intelligence. Instantly, technology that had after been supplied only to professionals was out there to any person with a web connection. The enthusiasm demonstrates no indicators of abating, and AI-generated illustrations or photos have gained a major pictures competition, designed the title credits of a tv sequence and tricked people into believing the pope stepped out in a trendy puffer coat. But critics have mentioned how coaching the algorithms on existing is effective could probably infringe on copyright, and working with them could place artists’ jobs in jeopardy. Generative AI also hazards supercharging faux news: the pope coat was entertaining, but a generated photograph supposedly displaying an assault on the Pentagon briefly encouraged a dip in the inventory industry.
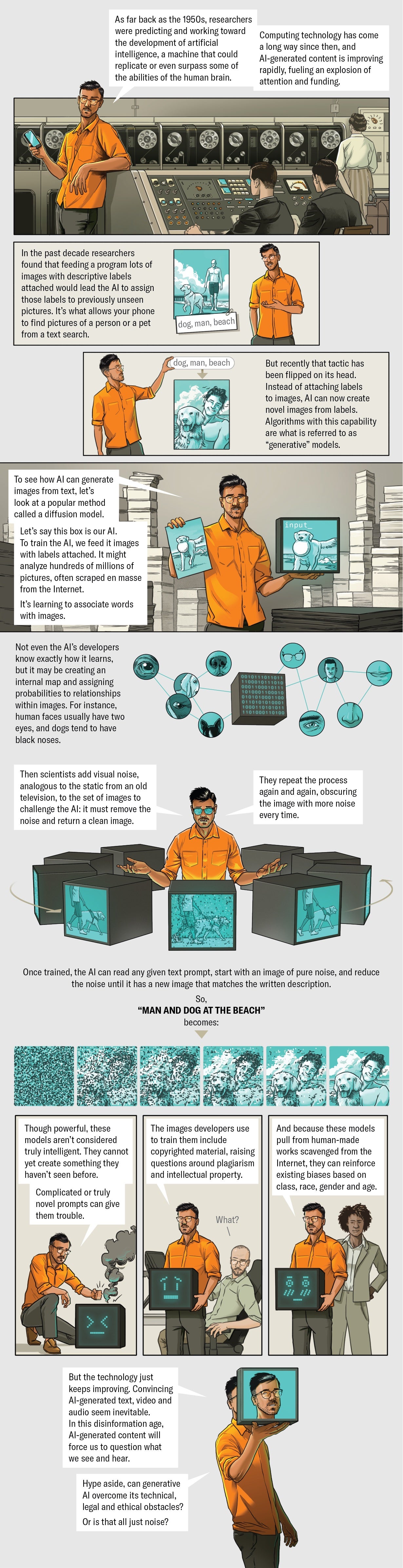
How did applications these as DALL-E 2, Midjourney and Secure Diffusion get to be so very good all at at the time? Whilst AI has been in advancement for decades, the most common of present-day impression generators use a strategy referred to as a diffusion product, which is relatively new on the AI scene. Here is how it operates:


This post was originally released with the title “How AI Generates Illustrations or photos from Text” in Scientific American 329, 3, 66-67 (October 2023)
doi:10.1038/scientificamerican1023-66
ABOUT THE Creator(S)

[ad_2]
Source hyperlink





